什么是REST
- Rest就是Representational State Transfer(状态表述转换)的简写
- 它描述了Webyingyong到底是怎么样设计才算是优良的,这里定义了以下三点:
- 一组网页的网络
- 在这些网页上,用户可以通过点击链接来前进(状态转换)
- 点击链接的结果是下一个网页(表示程序的下一个状态)被传输到用户那里,并渲染好给用户。
- Rest是一种架构风格,而不是规范或者标准,它需要使用一些规范、协议或者标准来实现这种架构风格,但它又与协议无关。Json和Http并不是Rest强制使用的,只是比较多的人用Json和Http来实现Rest架构风格。
Rest的优点
- 性能:由于Rest在通讯上是比较简单和高效的。
- 组件交互的可扩展性:一般分布式都有这个优点。
- 组件的可修改性:关注点分离,可以使各个组件以最小的成本和风险进行修改(各自进化)。
- 可移植性:Rest跟平台或技术都无关,任何平台都可以使用Rest风格来构建应用。
- 可靠性:Rest提出的是一种无状态约束,这种约束就可以在系统发生故障后轻松地恢复系统。像传统的Mvc就是有状态的,即Cookie和Session
- 可视性
Rest的约束
- 客户端-服务器(前后端分离)
- 无状态:服务器无须记住客户端的状态,即客户端会记录自己的状态
- 统一的资源接口/界面
- 资源的标识(URI)
- 通过表述来对资源进行操纵
- 带有自我描述信息
- 超媒体作为应用程序状态的引擎(HATEOAS)
- 多层系统 :系统中的每一层只知道自己的上一层或下一层。
- 可缓存:缓存响应数据,可以减少客户端感知资源的响应时间,提高可用性和可靠性,客户端可以选择从缓存或数据源获取数据。
- 按需编码(可选约束)
Richardson成熟度模型
- Level0,POX沼泽:只使用了Http协议
- Level1,资源:每个资源都映射到不同的URI,但Http动词没有用对
- Level2,动词:正确地使用了Http动词
- Level3,超媒体:支持HATEOAS
- 当WebApi达到Level3后,才有可能是一个Restful Api。
资源命名
使用名词,而不是动词
比如:我想获取系统中所有地用户,错误地URI:api/getusers
在Rest中,获取是一个动词,应该由Http动词来表示,所以正确的URI是:GET api/users
要体现资源的结构/关系
- 假如后端Api由若干种资源,而用户这个资源于其他的资源并没有直接的关系,这样的话获取用户资源的URI应该是api/users,而不是api/products/users,因为user和product没有直接的关系。
- 通过id获取单个用户的URI应该是:api/users/{userId}
- 这样写的好处是可以让Api具有很好的可预测性和一致性。
例子:获取公司下面的员工信息和某一个员工的信息
URI分别是:
获取公司下面的员工信息:api/companies/{companyId}/employees
获取公司下面某一个员工的信息:
api/companies/{companyId}/employees/{employeeId}
这样就能体现公司资源和员工资源的关系
自定义查询
- 有一些操作并不是针对于资源的,而是对资源的获取加以条件的,例如:排序、过滤、分页等,对于这些条件查询一般都是用查询字符串(query string)来表示
例子:获取所有的用户信息,并按照年龄从小到大进行排列
正确的做法是:api/users?orderby=age
例外
- 有一些需求总是无法满足Restful的约束,比如:想获取系统里所有用户的数量。
- 妥协的做法:api/users/total_amount_of_user
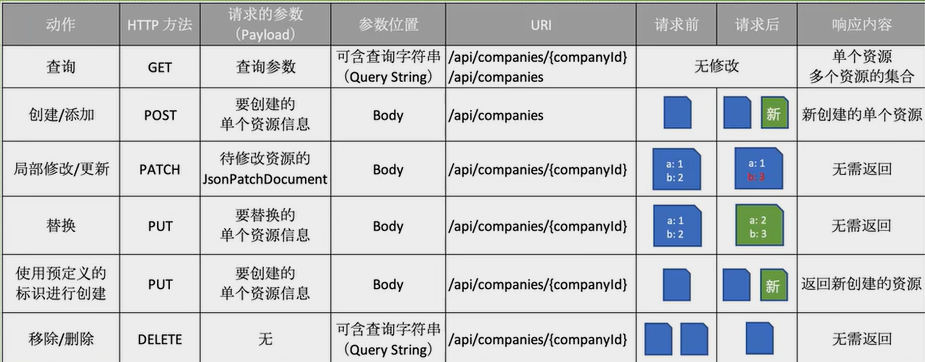
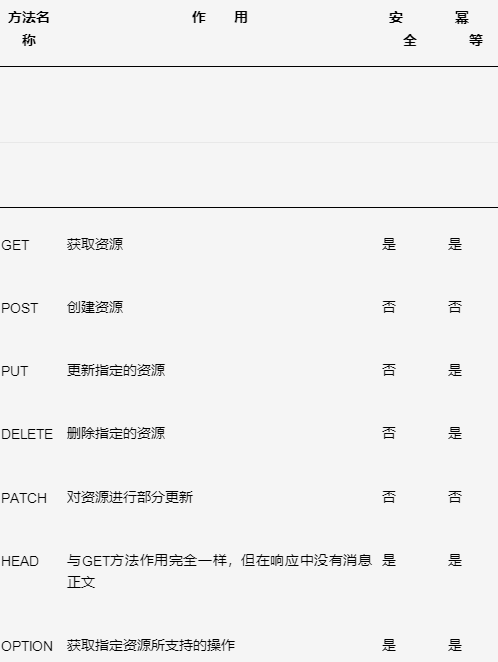
Http方法
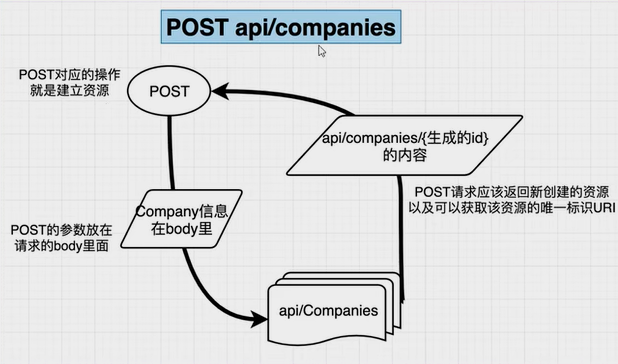
- 不同的动作可以作用于相同的资源URI,下面使用公司的资源来表示各个Http方法是如何使用的
POST:添加一个公司信息
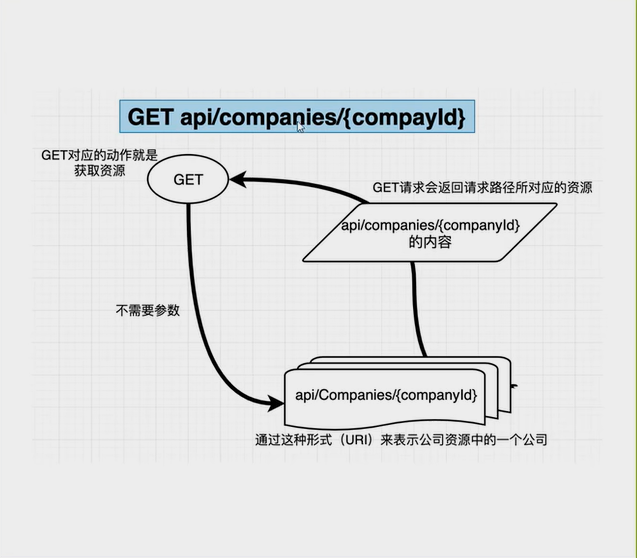
GET
- 获取一个公司信息
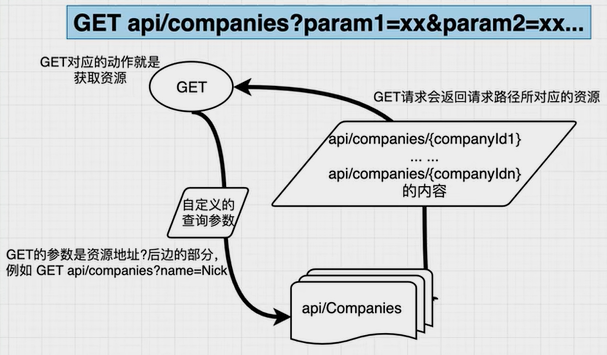
- 获取集合资源(获取符合查询条件的公司资源)
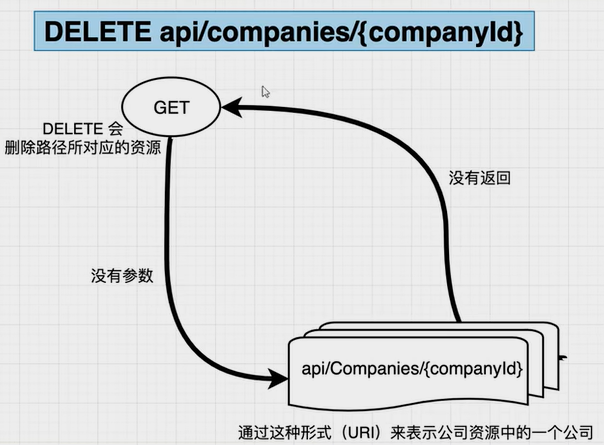
DELETE:删除一个公司信息
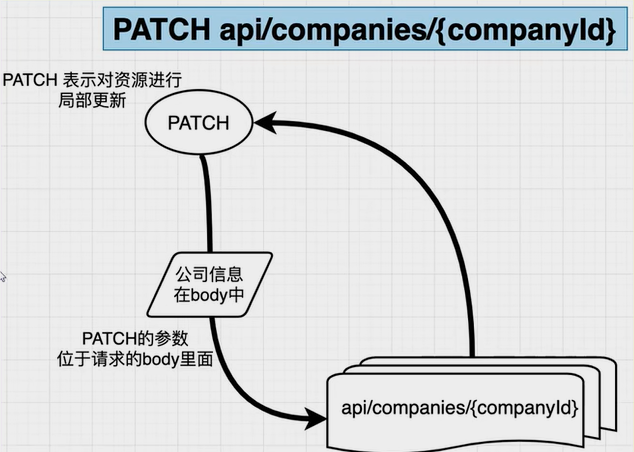
PATCH:更新公司信息
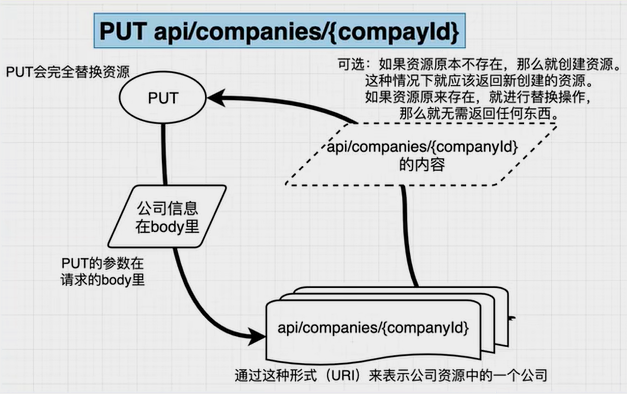
PUT:替换公司信息
HEAD
- HEAD和GET几乎是一样的,只有一点不同:HEAD的API不应该返回相应的body,HEAD可以用来获取资源上的一些信息。
- 比如在一个支持缓存的系统中,Head就可以返回某一个资源是否是有效的或者资源最近是否被更新了,也可以用来检查URI是否存在,即资源是否存在。
- Head的代码基本上和Get是一致的,但它并不返回响应体
OPTIONS
- 用来获取针对某个Api中的资源所支持的操作
- 一般在响应消息头中添加Allow来表示所允许的Http方法
总结:
Http状态码
Http状态码主要是要来判断请求是否执行成功了,如果请求失败了,那失败的原因是什么,也就是谁应该为它负责。
状态码可分为以下5类:
- 1xx:信息,服务器收到请求,需要请求方继续执行操作。
- 2xx:成功,服务器成功执行客户端所请求的操作。
- 3xx:重定向,需要进一步的操作以完成请求
- 4xx:客户端错误,请求包含语法错误或请求内容不正确。
- 5xx:服务端错误,服务器在处理请求的过程中发生了错误。
以下是常见的状态码:




- 还有一个422Unprocessable entity状态码,它通常是用来表示语义上有错误,即在服务器实体验证失败时可返回该状态码。
内容协商
- 针对一个响应,当有多种表述格式可用时(json、xml等),如何选取一个最佳的表述,这就需要进行内容协商。
- 当Http服务器对请求返回响应时,它不仅返回资源本身,也应在响应中指明资源的内容类型(Media Type),比如text/html,表示内容类型为text/html,前面text为主类型,html为子类型,当请求一个图片资源时,可以将它标记为image/jpg或image/gif
常见的媒体类型

Accept:输出
- 表示客户端可接受的响应内容类型
- 如果请求中没有Accept的值,则服务器就会返回Api默认的媒体类型数据,当客户端就有可能无法解析服务器发送的数据,如果客户端添加了Accept Header,但服务器并不支持客户端请求的媒体类型,这时候,服务器就应该返回406Not Acceptable来告诉客户端不支持这个媒体类型的数据。
Content-Type:输入
- 表示请求正文的Media Type(一般用于POST和PUT请求中)
- 在Http Header中,Content-Type一般有三种:
application/x-www-form-urlencoded:数据被编码为名称/值对。这是标准的编码格式。multipart/form-data: 数据被编码为一条消息,页上的每个控件对应消息中的一个部分。text/plain: 数据以纯文本形式(text/json/xml/html)进行编码,其中不含任何控件或格式字符。postman软件里标的是RAW。
- 当action为get时候,浏览器用
x-www-form-urlencoded的编码方式把form数据转换成一个字串(name1=value1&name2=value2…),然后把这个字串追加到url后面,用?分割,加载这个新的url。 - 当action为post时候,浏览器把form数据封装到http body中,然后发送到server。 如果没有
type=file的控件,用默认的application/x-www-form-urlencoded就可以了。 但是如果有type=file的话,就要用到multipart/form-data了。 - 当action为post且Content-Type类型是
multipart/form-data,浏览器会把整个表单以控件为单位分割,并为每个部分加上Content-Disposition(form-data或者file),Content-Type(默认为text/plain),name(控件name)等信息,并加上分割符(boundary)。
Http Header
- Http Header分为请求头和响应头两部分
- 常见的请求消息头



- 常见的响应消息头