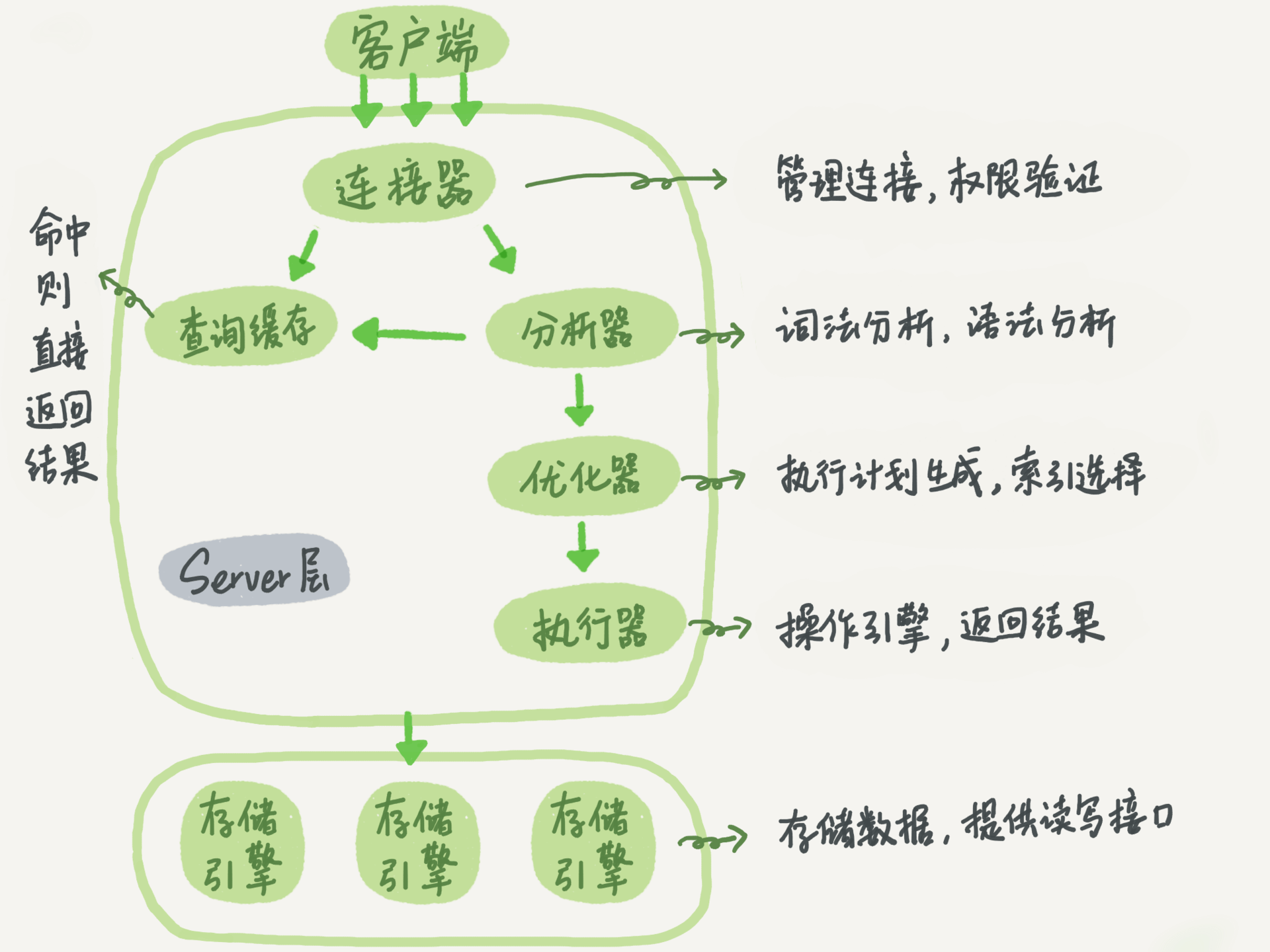
- 连接器:管理链接,权限验证
- 查询缓存:命中则直接返回结果
- 分析器:词法分析、语法分析
- 优化器:语句执行计划生成、索引选择
- 执行器:操作引擎,返回结果
- 存储引擎:存储数据,提供读写接口
日志模块
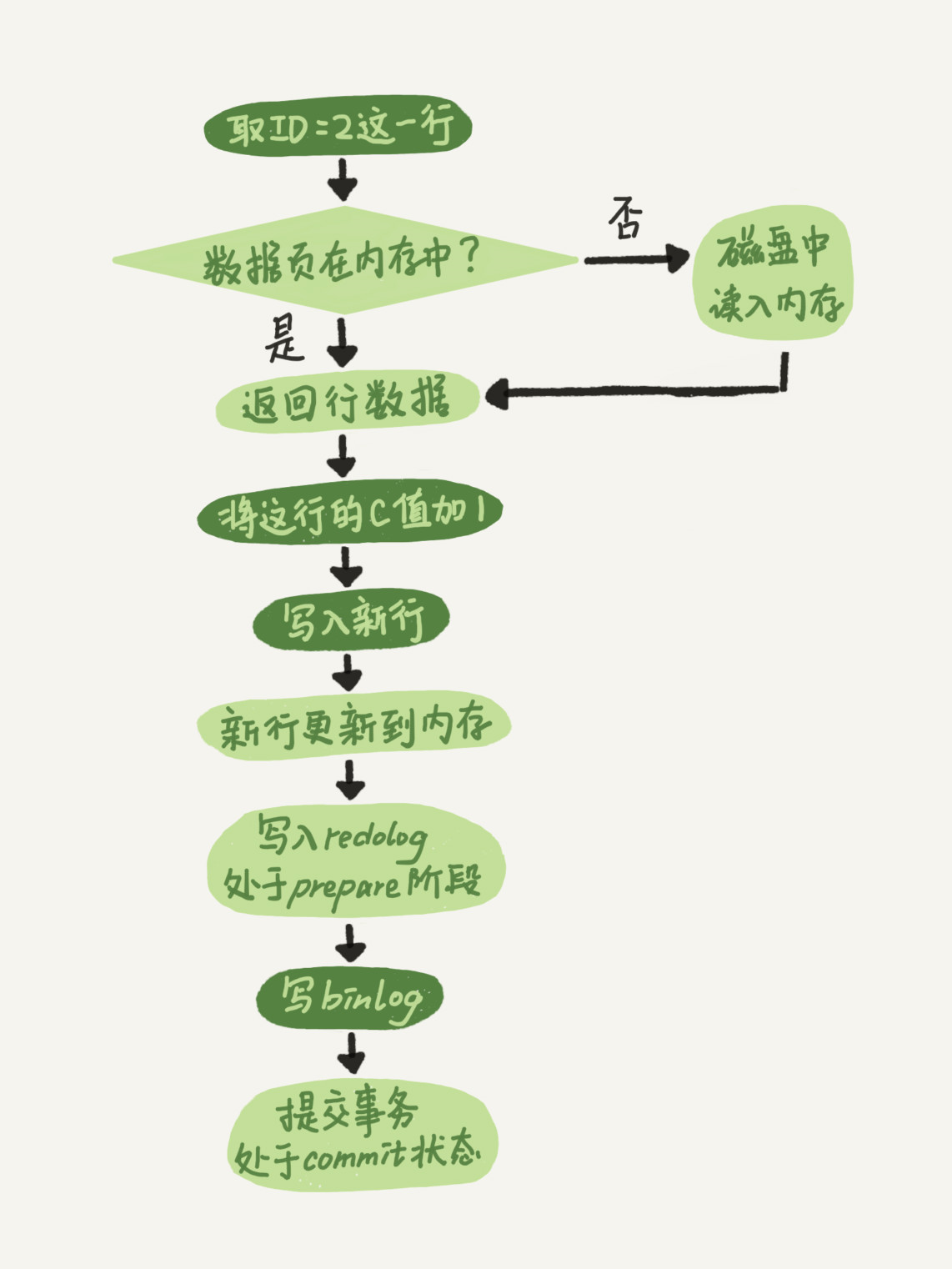
- redo log(重做日志):当有一条记录需要更新时,InnoDB引擎会先把记录写到redo log,并更新内存,当innodb有空闲的时候会做这个更新
- bin log(归档日志):是用来做数据库备份的,当你需要恢复数据库时,可以使用binlog恢复临时库,再把表数据从临时库取出来,按需要恢复到线上库。
- 两阶段提交:在写入redo log时会将redo log的状态改为prepare状态,然后再进行写bin log,之后提交事务,会把redo log的状态改为commit状态,这就叫两阶段提交。
- 引入两阶段提交的目的是为了让两份日志之间的逻辑一致,即避免系统崩溃,数据丢失的情况。
- 而日志有的时候可以一天一备或一周一备,这个各有好处。
- 把innodb_flush_log_at_trx_commit这个参数设置为1时,表示每次的redo log都会持久化到磁盘,而sync_binlog这个参数设置为1时,可以保证MySql异常重启binlog不会丢失。
日志的类型
- MySql的日志类型分为物理日志和逻辑日志,物理日志存储了数据被修改的值,而逻辑日志存储了逻辑Sql修改语句,redolog是物理日志,而binlog是逻辑日志
redolog
- redolog是物理日志,物理日志存储的是数据被修改的值,所以在使用redolog来恢复数据库时,恢复的速度远超过逻辑日志。
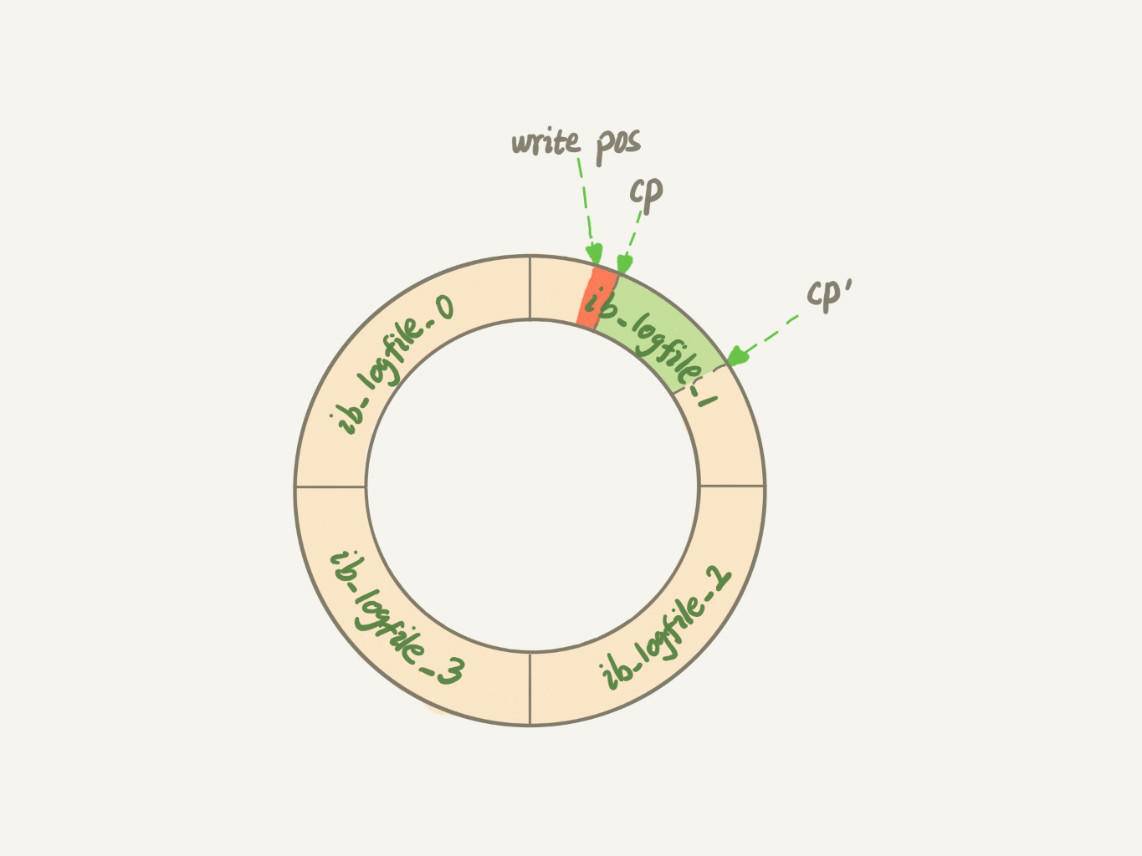
- cp(checkpoint):表示使用redolog flush的起始位置,checkpoint所做的事就是把脏页给刷新回磁盘。所以,当DB重启恢复时,只需要恢复checkpoint之后的数据。这样就能大大缩短恢复时间。
- write pos:数据写入redolog的位置,当redolog的write pos接近cp时,表示redolog要满了,这时InnoDB必须停下手中的工作,进行刷脏页,腾出一些空余空间才能继续写redolog。
- redolog其实分为两个部分:
- 重做日志缓冲(redo log buffer),这部分内容存在于内存中。
- 重做日志文件(redo log file)。这部分内容存在于磁盘中。
- 这样的设计同样也是为了调和内存与磁盘的速度差异。InnoDB写入磁盘的策略可以通过
innodb_flush_log_at_trx_commit这个参数来控制。fsync表示redolog写入磁盘操作

- 当该值为1时,当然是最安全的,但是数据库性能会受一定影响;为0时性能较好,但是会丢失掉master thread还没刷新进磁盘部分的数据。
- master thread:这是InnoDB一个在后台运行的主线程,它做的主要工作包括但不限于:刷新日志缓冲,合并插入缓冲,刷新脏页等。
- master thread大致分为每秒运行一次的操作和每10秒运行一次的操作。master thread中刷新数据,属于checkpoint的一种。所以如果在master thread在刷新日志的间隙,DB出现故障那么将丢失掉这部分数据。
binlog的模式
- mysql复制主要有三种方式:基于SQL语句的复制(statement-based replication, SBR),基于行的复制(row-based replication, RBR),混合模式复制(mixed-based replication, MBR)。对应的,binlog的格式也有三种:STATEMENT,ROW,MIXED。
STATEMENT模式(SBR)
- 每一条会修改数据的sql语句会记录到binlog中。优点是并不需要记录每一条sql语句和每一行的数据变化,减少了binlog日志量,节约IO,提高性能。缺点是在某些情况下会导致master-slave中的数据不一致(如sleep()函数, last_insert_id(),以及user-defined functions(udf)等会出现问题)
ROW模式(RBR)
- 不记录每条sql语句的上下文信息,仅需记录哪条数据被修改了,修改成什么样了。而且不会出现某些特定情况下的存储过程、或function、或trigger的调用和触发无法被正确复制的问题。缺点是会产生大量的日志,尤其是alter table的时候会让日志暴涨。
MIXED模式(MBR)
- 以上两种模式的混合使用,一般的复制使用STATEMENT模式保存binlog,对于STATEMENT模式无法复制的操作使用ROW模式保存binlog,MySQL会根据执行的SQL语句选择日志保存方式。