准备测试数据
- 通过 Linux 命令行进入 SequoiaDB Shell;
- 通过 javascript 语言连接协调节点,获取数据库连接;
1
| var db = new Sdb("localhost", 11810);
|
1
| db.createDomain("company_domain", [ "group1", "group2", "group3" ], { AutoSplit: true } );
|
1
| db.createCS("company", { Domain: "company_domain" } );
|
1
| db.company.createCL("employee", { "ShardingKey": { "_id": 1 }, "ShardingType": "hash", "ReplSize": -1, "Compressed": true, "CompressionType": "lzw", "AutoSplit": true, "EnsureShardingIndex": false } );
|
- 写入测试数据。使用 javascript 的 for 循环向 employee 表写入1000条记录;
1
2
3
4
| for (var i = 0; i < 1000; i++)
{
db.company.employee.insert( { empno: i, ename: "TEST", age: 20 } );
}
|
全量备份与增量备份
当前版本中,数据库备份支持全量备份和增量备份。全量备份过程中会阻塞数据库变更操作,即数据插入、更新、删除等变更操作会被阻塞直到全量备份完成才会执行;增量备份过程中不阻塞数据库变更操作。
- 全量备份:备份整个数据库的配置、数据和日志(可选);
- 增量备份:在上一个全量备份或增量备份的基础上备份新增的日志和配置;增量备份需要保证日志的连续性和一致性,如果日志不连续,或日志 Hash 校验不一致,则增量备份失败。因此,周期性的增量备份需要计算好日志和周期的关系,以防止日志覆写。
在协调节点上对整个数据库或指定组进行备份,默认是只在该数据组主节点上进行备份。Catalog 编目组的名称固定为 SYSCatalogGroup。
使用 Sdb.backup() 命令可以进行备份。具体参数说明参考
全量备份
1
| db.backup( { Name: "cluster_backup", Path: "/tmp/%g", Overwrite: true, Description: "full backup" } );
|
Note:
Path 中的 “%g”是一个通配符代表group name,当在协调节点上执行命令使用该参数时,需要使用通配符,以避免所有的节点往同一个路径下进行操作而导致未知IO错误。
1
2
3
4
| ls /tmp
ls /tmp/group1/
ls /tmp/group2/
ls /tmp/group3/
|
操作截图:

可以看到,在/tmp目录下有 4 个文件夹,SYSCatalogGroup,group1,group2 和 group3 ,分别对应编目节点组,数据组 1 ,数据组 2,数据组 3。
增量备份
- 通过 Linux 命令行进入 SequoiaDB Shell;
- 通过 javascript 语言连接协调节点,获取数据库连接;
1
| var db = new Sdb("localhost", 11810);
|
1
2
3
4
| for (var i = 1000; i < 1500; i++)
{
db.company.employee.insert( { empno: i, ename: "TEST", age: 20 } );
}
|
- 执行增量备份;这里EnsureInc表示为增量备份
1
| db.backup( { Name: "cluster_backup", Path: "/tmp/%g", EnsureInc: true } );
|
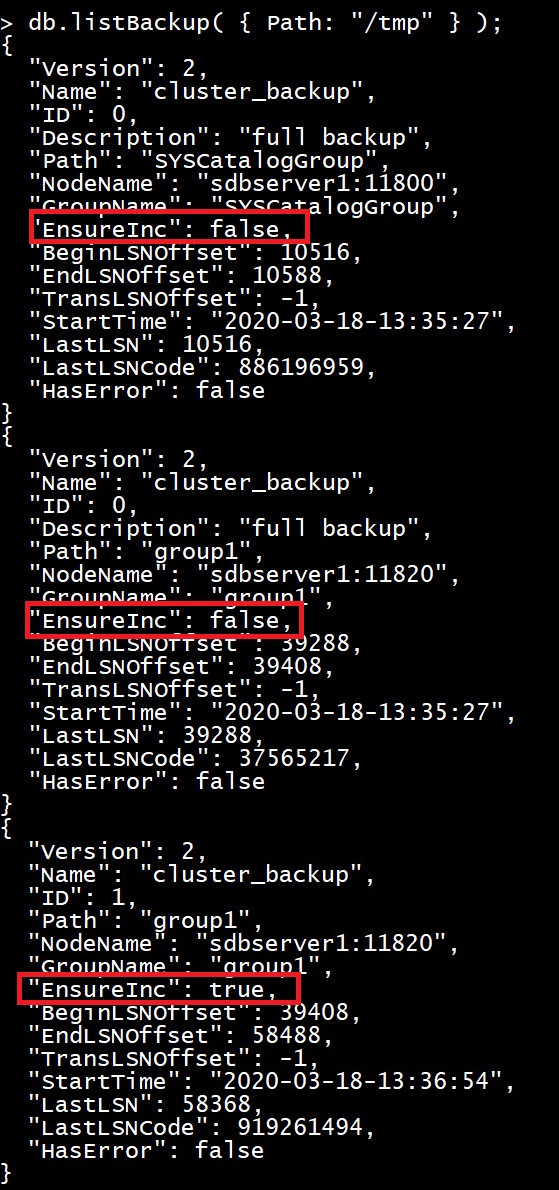
1
| db.listBackup( { Path: "/tmp" } );
|
操作截图:
1
2
3
| ls /tmp/group1/
ls /tmp/group2/
ls /tmp/group3/
|
Note:
增量备份的备份名应和上一次全量备份保持一致。
操作截图:

可以看到,相比于第一次备份生成的文件,本次增量备份在 group1 ,group2 和 group3 目录下新生成了两个文件。
全量恢复与增量恢复
使用备份的数据恢复当前集群中的节点或者恢复到离线数据的说明:
- 恢复当前集群中的节点:执行数据恢复必须确保该节点对应的数据组已停止运行,数据恢复首先会清空原节点的所有数据和日志,然后从备份的数据中恢复配置、数据和日志。
- 恢复到离线数据:可以将全量备份和增量备份的数据不断合并成一份与节点内数据完全相同格式的离线数据,可以在原节点故障后使用该离线数据实现快速恢复。
如果一个分区组包含多个数据节点,必须停止该组中每个数据节点并进行恢复。如果将备份的数据恢复至非备份数据节点,添加 –isSelf 参数并设置成 false,同时设置相关的配置参数。
恢复分区组其他节点数据,恢复方式有以下几种:
- 删除该分区组中其它数据节点的所有 .data 和 .idx 、.lobd、.lobm 文件以及 replicalog 日志,节点启动后会自行同步数据。
- 拷贝恢复节点的所有 .data 和 .idx 、.lobd、.lobm文件拷贝至其它数据节点的数据目录和索引目录下,以及将该节点的所有 replicalog 日志拷贝至其它数据节点的 replicalog 日志目录下。
- 将备份文件拷贝至其它数据节点,并通过 sdbrestore 工具恢复。
使用 sdbrestore 可以进行数据恢复,具体参数说明参考下面这个链接:(sdbrestore)[http://doc.sequoiadb.com/cn/sequoiadb-cat_id-1432190666-edition_id-0]
全量恢复
- 通过 Linux 命令行进入 SequoiaDB Shell;
- 通过 javascript 语言连接协调节点,获取数据库连接;
1
| var db = new Sdb("localhost", 11810);
|
1
2
3
4
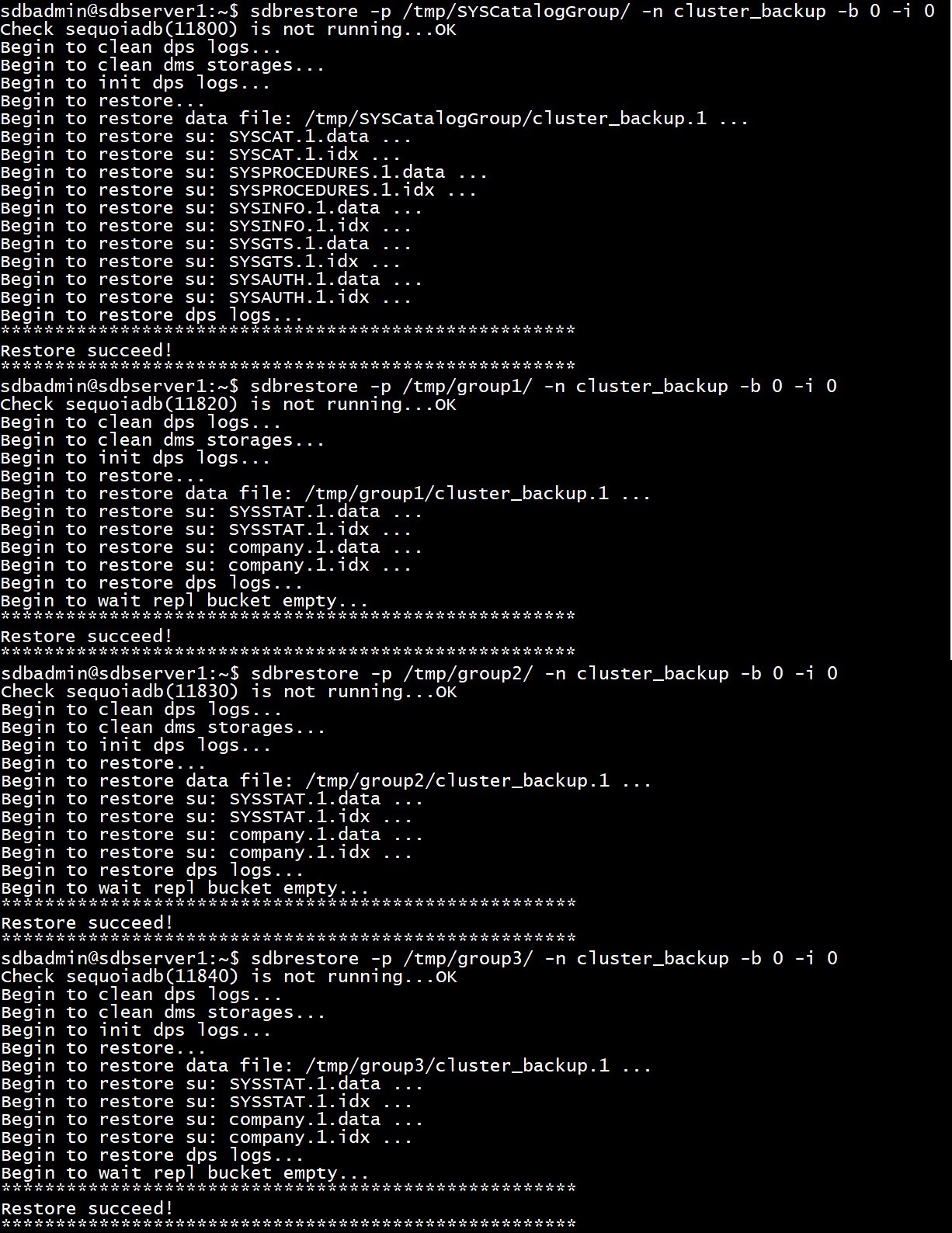
| sdbrestore -p /tmp/SYSCatalogGroup/ -n cluster_backup -b 0 -i 0
sdbrestore -p /tmp/group1/ -n cluster_backup -b 0 -i 0
sdbrestore -p /tmp/group2/ -n cluster_backup -b 0 -i 0
sdbrestore -p /tmp/group3/ -n cluster_backup -b 0 -i 0
|
Note:
-b 后面带的参数代表需要从第几次备份开始恢复,从 0 开始算起,缺省由系统自动计算 ( -1 )。
-i 后面带的参数代表需要恢复到第几次数据备份,从 0 开始算起,缺省恢复到最后一次 ( -1 )。
Note:
执行全量恢复时要先停节点,恢复完后再启动,为了方便,将整个集群停下来 恢复的时候需要按节点恢复,分别是编目节点,数据组1,数据组2,数据组3
操作截图:
- 检查数据是否正确,此时只能查到集合中的第一次插入的数据;
通过 Linux 命令行进入 SequoiaDB Shell;
通过 javascript 语言连接协调节点,获取数据库连接;
1
| var db = new Sdb("localhost", 11810);
|
统计 company.employee 数据量;
1
| db.company.employee.count();
|
操作截图:

退出 SequoiaDB Shell;
此时只能看到第一次插入的 1000 条记录,第二次插入的 500 条记录看不到。
增量恢复
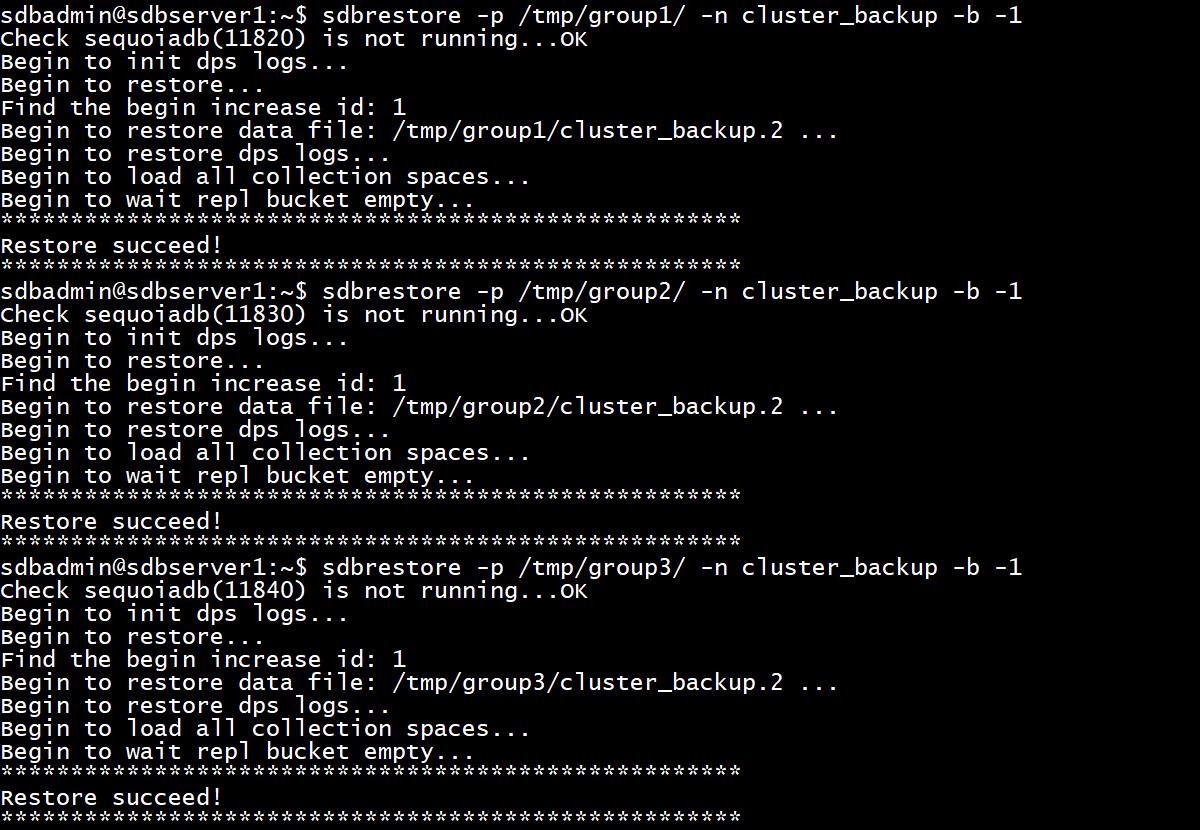
1
2
3
| sdbrestore -p /tmp/group1/ -n cluster_backup -b -1
sdbrestore -p /tmp/group2/ -n cluster_backup -b -1
sdbrestore -p /tmp/group3/ -n cluster_backup -b -1
|
操作截图:
- 检查数据是否正确,此时能看到第二次插入的记录; 通过 Linux 命令行进入 SequoiaDB Shell;
通过 javascript 语言连接协调节点,获取数据库连接;
1
| var db = new Sdb("localhost", 11810);
|
统计 company.employee 数据量;
1
| db.company.employee.count();
|
操作截图:

退出 SequoiaDB Shell;