创建域、集合空间、集合
- 通过 Linux 命令行进入 SequoiaDB Shell;
- 通过 javascript 语言连接协调节点,获取数据库连接;
1
| var db = new Sdb("localhost", 11810);
|
1
| db.createDomain("company_domain", [ "group1", "group2", "group3" ], { AutoSplit: true } );
|
1
| db.createCS("company", { Domain: "company_domain" } );
|
1
| db.company.createCL("employee", { "ShardingKey": { "_id": 1 }, "ShardingType": "hash", "ReplSize": -1, "Compressed": true, "CompressionType": "lzw", "AutoSplit": true, "EnsureShardingIndex": false } );
|
写入测试数据
使用 JavaScript 的 for 循环向 employee 表写入 1000 条记录,用于测试。
1
2
3
4
| for (var i = 0; i < 1000; i++)
{
db.company.employee.insert( { ename: "TEST", age: 20 } );
}
|
集群扩容
1
| db.getRG("group4").createNode("sdbserver1", 11850, "/opt/sequoiadb/database/data/11850/");
|
Note:
createNode() 方法的定义格式有四个参数:host,service,dbpath,config,如上表所示,host,dbpath 为字符串类型,Service 类型支持 int 或 string ,必填;最后一个是 Json 对象,选填,如配置日志大小,是否打开事务等,具体可参考数据库配置。
格式:( “<主机名>”, “<端口号>”, “<节点路径>, “[ {key : value, … } ] )
createNode 方法的详细说明请参考:createNode 方法说明。
1
| db.getRG("group4").start();
|
- 数据域 company_domain 增加数据组;
1
| db.getDomain("company_domain").addGroups( { Groups: [ 'group4' ] } );
|
1
2
3
| db.company.employee.split("group1", "group4", 25);
db.company.employee.split("group2", "group4", 25);
db.company.employee.split("group3", "group4", 25);
|
Note:
以上split的含义时是把 group1、group2 和 group3 上的数据分别移25%到 group4 上。 split 方法的详细说明请参考:split 方法说明。
分析数据分布
1
| var db1 = new Sdb("localhost", 11820);
|
1
| db1.company.employee.count();
|
1
| var db2 = new Sdb("localhost", 11830);
|
1
| db2.company.employee.count();
|
1
| var db3 = new Sdb("localhost", 11840);
|
1
| db3.company.employee.count();
|
1
| var db4 = new Sdb("localhost", 11850);
|
1
| db4.company.employee.count();
|
操作截图:
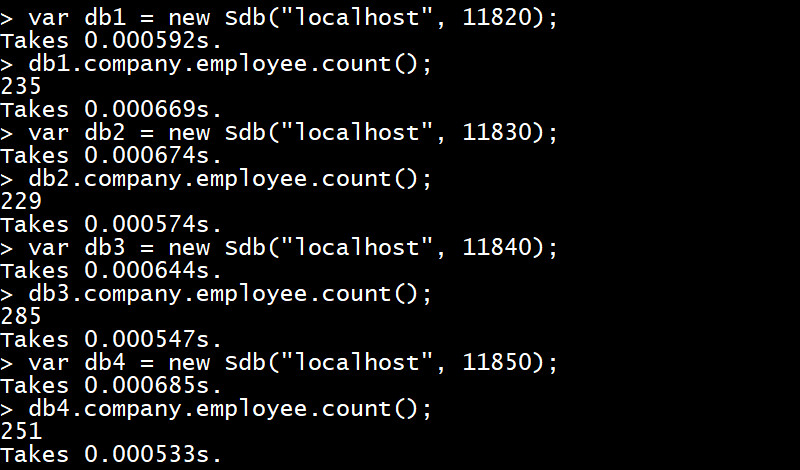
可以看到,四个数据组上的记录数基本为平均分布。
集群缩容
- 本小节展示把 group4 的数据迁移到其他节点后把其剔出 company_domain 域,并把 group4 删除的操作。
- 将集合1在新数据组上的数据迁移回旧的数据组;
1
2
3
| db.company.employee.split("group4", "group1", 33);
db.company.employee.split("group4", "group2", 50);
db.company.employee.split("group4", "group3", 100);
|
- 统计 group1,group2,group3 数据量,它们加起来等于 1000 ;
1
2
3
| db1.company.employee.count();
db2.company.employee.count();
db3.company.employee.count();
|
- 把 group4 移出 company_domain 域;
1
| db.getDomain("company_domain").removeGroups( { Groups: [ 'group4' ] } );
|
1
| db.company.employee.count();
|
数据量为1000,说明数据被正确迁移回来了。
关闭数据库连接
- 关闭 db、db1、db2、db3、db4 数据库连接;
1
2
3
4
5
| db.close();
db1.close();
db2.close();
db3.close();
db4.close();
|
操作截图:
可以看到,group4 已经从集群中剔除。