从Shark说起
- Shark即Hive on Spark,为了实现与Hive兼容,Shark在HiveQL方面重用了Hive中的HiveQL解析、逻辑执行计划翻译、执行计划优化等逻辑,可以近似认为仅将物理执行计划从MapReduce作业替换成了Spark作业,通过Hive的HiveQL解析,把HiveQL翻译成Spark上的RDD操作。
- Shark的设计导致了两个问题:一是执行计划优化完全依赖于Hive,不方便添加新的优化策略;二是因为Spark是线程级并行,而MapReduce是进程级并行,因此,Spark在兼容Hive的实现上存在线程安全问题,导致Shark不得不使用另外一套独立维护的打了补丁的Hive源码分支。
- Shark的实现继承了大量的Hive代码,因而给优化和维护带来了大量的麻烦,特别是基于MapReduce设计的部分,成为整个项目的瓶颈。因此,在2014年的时候,Shark项目中止,并转向Spark SQL的开发。
Spark SQL简介
- Spark SQL的架构如图所示,在Shark原有的架构上重写了逻辑执行计划的优化部分,解决了Shark存在的问题。Spark SQL在Hive兼容层面仅依赖HiveQL解析和Hive元数据,也就是说,从HQL被解析成抽象语法树(AST)起,就全部由Spark SQL接管了。Spark SQL执行计划生成和优化都由Catalyst(函数式关系查询优化框架)负责。
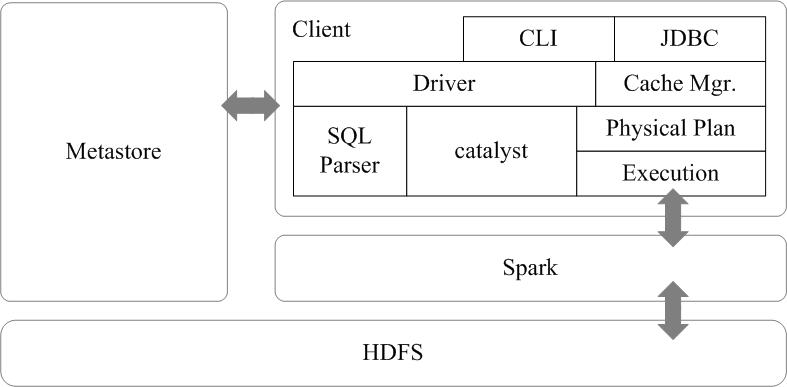
- Spark SQL增加了SchemaRDD(即带有Schema信息的RDD),使用户可以在Spark SQL中执行SQL语句,数据既可以来自RDD,也可以来自Hive、HDFS、Cassandra等外部数据源,还可以是JSON格式的数据。Spark SQL目前支持Scala、Java、Python三种语言,支持SQL-92规范。从Spark1.2 升级到Spark1.3以后,Spark SQL中的SchemaRDD变为了DataFrame,DataFrame相对于SchemaRDD有了较大改变,同时提供了更多好用且方便的API,如图16-13所示。
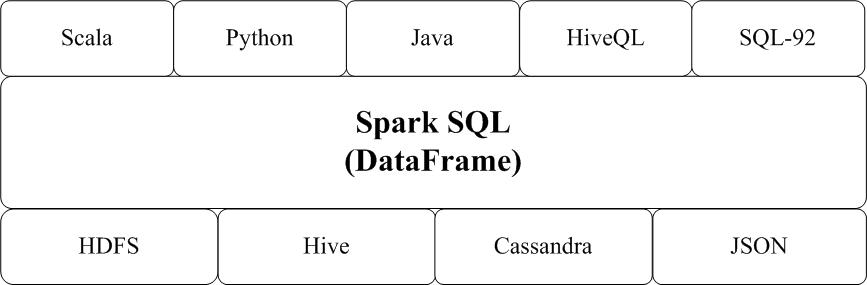
- Spark SQL可以很好地支持SQL查询,一方面,可以编写Spark应用程序使用SQL语句进行数据查询,另一方面,也可以使用标准的数据库连接器(比如JDBC或ODBC)连接Spark进行SQL查询,这样,一些市场上现有的商业智能工具(比如Tableau)就可以很好地和Spark SQL组合起来使用,从而使得这些外部工具借助于Spark SQL也能获得大规模数据的处理分析能力。
DataFrame简介
- DataFrame就是带有Schema信息的RDD,它的推出,让Spark具备了处理大规模结构化数据的能力,不仅比原有的RDD转化方式更加简单易用,而且获得了更高的计算性能。Spark能够轻松实现从MySQL到DataFrame的转化,并且支持SQL查询。
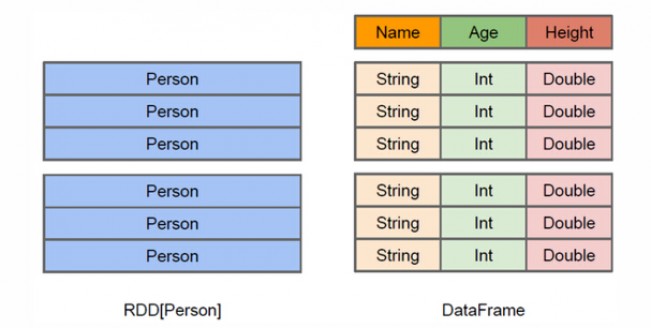
- 从上面的图中可以看出DataFrame和RDD的区别。RDD是分布式的 Java对象的集合,比如,RDD[Person]是以Person为类型参数,但是,Person类的内部结构对于RDD而言却是不可知的。DataFrame是一种以RDD为基础的分布式数据集,也就是分布式的Row对象的集合(每个Row对象代表一行记录),提供了详细的结构信息,也就是我们经常说的模式(schema),Spark SQL可以清楚地知道该数据集中包含哪些列、每列的名称和类型。
- 和RDD一样,DataFrame的各种变换操作也采用惰性机制,只是记录了各种转换的逻辑转换路线图(是一个DAG图),不会发生真正的计算,这个DAG图相当于一个逻辑查询计划,最终,会被翻译成物理查询计划,生成RDD DAG,按照之前介绍的RDD DAG的执行方式去完成最终的计算得到结果。
DataFrame的创建
- DataFrame有三种创建方式:
- 使用SparkSession读取文件来创建DataFrame;
- 使用自定义Schema的方式来创建DataFrame;
- 从已有的RDD转换生成DataFrame。
使用SparkSession来创建DataFrame
从Spark2.0以上版本开始,Spark使用全新的SparkSession接口替代Spark1.6中的SQLContext及HiveContext接口来实现其对数据加载、转换、处理等功能。SparkSession实现了SQLContext及HiveContext所有功能。
SparkSession支持从不同的数据源加载数据,并把数据转换成DataFrame,并且支持把DataFrame转换成SQLContext自身中的表,然后使用SQL语句来操作数据。SparkSession亦提供了HiveQL以及其他依赖于Hive的功能的支持。
创建一个people.json和people.txt:
- people.json文件的内容如下:
1
2
3{"name":"Michael"}
{"name":"Andy", "age":30}
{"name":"Justin", "age":19}- people.txt文件的内容如下:
1
2
3Michael, 29
Andy, 30
Justin, 19读取people.json文件中的内容创建DF:
1 | from pyspark.sql.session import SparkSession |
使用自定义Schema的方式来创建DataFrame
1 | from pyspark.sql.types import Row, StructType, StructField, StringType, DataType |
从已有的RDD转换生成DataFrame
1 | from pyspark import SparkConf, SparkContext |
转载于:子雨大数据